Schemas are a critical component of the service
contract. Abstraction is a key
aspect of an SOA, and a well-built schema provides a sufficient level
of opaqueness to the underlying service processing. Interoperability,
another vital piece of a far-reaching service, should be taken into
consideration at the earliest phases of schema design. Finally, the
concept of reusability is readily embraced in schema design.
Let's
now look at a series of ways as to we can take these service-oriented
principles and apply them to schemas designed in BizTalk Server 2009.This includes actions such as enrolling into a trial,
participating in a screening, and withdrawing from the trial.
Designing schemas based on service type
We defined three different service types:
RPC Services: Messages correspond to actions we wish to perform.
Document Services: The data entity is transmitted, absent instruction of what to do with it.
Event Services: Messages represent explanations of events that have occurred.
The BizTalk WCF Service Publishing Wizard, unlike the classic BizTalk Web Services Publishing Wizard, does not offer the option of Bare (document-style services) or Wrapped
(RPC-style services). All BizTalk-generated WCF endpoints exhibit a
document-centric pattern. Therefore, if you wanted to accept an
RPC-style WCF message into of BizTalk Server, you'd have to explicitly
build your request schema in that RPC fashion.
So how would you build this sort of schema for a "new enrollment" in our drug trial? We start out with a command root node name, and include the parameters we need to insert this record into our clinical trial system.
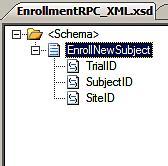
Notice by transmitting this sort of message, the caller gets the impression of invoking a function called EnrollNewSubject on my remote system.
What would a more document-centric design of this schema look like? In this case, we'd want to share the entire enrollment
entity with the service. That is, provide a fully encapsulated form of
the data object that relies on no existing context about this
interaction.
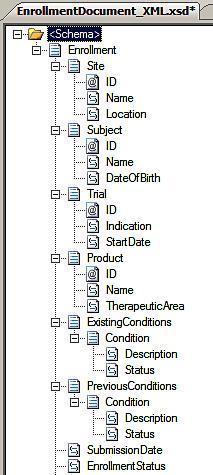
In
this schema, the root is the type of document being exchanged and no
indication is given as to what the service has to do with it.
Meanwhile, it contains a full spectrum of information about this
particular enrollment and should not require additional enrichment
prior to acting upon it.
How
do event-style message differ? In this case, the message is a
reflection of something of interest that has occurred.I mentioned that in some cases event messages trigger
callbacks to the source system for more information. However, do not
consider that scenario an excuse to distribute tiny, nondescript event
messages that contain nothing but foreign key pointers.
If
you choose to only send data pointers in an event message, you are
saying that either (a) the user doesn't need the actual data in order
to make decisions, or (b) the downstream consumer is guaranteed to have
access to the source system for data enrichment. I consider a
correctly-sized event message to be one that contains enough
information to be actionable.
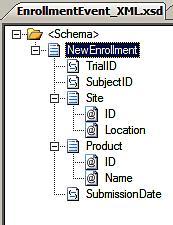
This schema is for the New Enrollment
event published by the business partner that manages the clinical trial
process. While it's certainly possible to include the "document" in an
event message, in my case above, I've chosen to include only a few
pieces of data that are most critical to event subscribers. Interest in
enrollments will be limited to the location of the clinical site, which
product is being administered, and which trial this is part of. If the
receiver of the event requires any more enrollment information than
this, then I'll ask them to seek it out in their own regional systems.
Critical point:
In
reality, these schema structure distinctions are purely architectural
ideals. We're really talking about how a message looks as it is
exchanged between endpoints. The name of a root node, or how exactly
the schema is structured doesn't directly relate to what the service is
capable of doing. However, the forethought that goes into deciding on a
more event-driven approach versus a RPC approach does impact how you
build the service and infrastructure that uses the service message.
When building any schema in a distributed architecture, the tricky concept of idempotence must be addressed. Wikipedia defines idempotence as:
In
computer science, the term idempotent is used to describe methods or
subroutine calls that can safely be called multiple times, as invoking
the procedure a single time or multiple times results in the system
maintaining the same state.
Source: http://en.wikipedia.org/wiki/Idempotence
Simply
put, because it's never a good idea to rely on the infrastructure
between distributed systems, the messages should support repeated
delivery without consequence. For instance, a typical request/response
query (such as getting the address of a customer) is idempotent. It
doesn't matter if I initiate this request fifteen times in a row, the
state of the customer's address remains static. However, if I execute a withdrawal command repeatedly, then I better expect my bank account to continually decrease.
So how do we account for this? The Enterprise Integration Patterns book from Hohpe and Woolf calls out two ways:
A
non-idempotent RPC message may demand that my salary was increased by
five thousand dollars. While I might appreciate that message
"accidentally" traveling through our payroll system five or six times,
my employer would not. An idempotent version of that message would
instead declare what the current salary number should be (such as fifty
thousand dollars) so that the repeated transmission would result in the
same value being present in the target system. However, this isn't
foolproof as it does not take into account the changes being made to
that same entity by other systems.
RPC
and document-style services can be quite prone to this problem. What if
you have repeated changes to an "enrollment" document published and the
message bus processes them out of order so that the latest one is
overwritten by the earlier one? You can try and exploit timestamps and
the like, but this remains a tricky issue.
One
way to avoid this is to rely on event messages with required lookups by
the subscriber. Deviating from our clinical trial scenario for a
moment, let's consider the life cycle of employee changes in an HR
system. A given employee record could get updated at a few distinct
intervals in the day, and the opportunity exists for messages to slip
out of sequence. However, if you have an event-style message that tells
subscribers that the employee's data has changed (and nothing else),
then the subscriber simply goes and pulls the latest employee profile
from the source system themselves. It doesn't matter if I send that
event message sixty times in a row; I'm not actually distributing any
state data that is dependent on arrival order. The downside to this
strategy is an increase in network traffic, and an assurance that all
subscribers can indeed access the source system.